RabbitMQ - 进阶
z 2019-09-21
RabbitMQ
# 使用场景
异步、削峰、解耦
# 问题
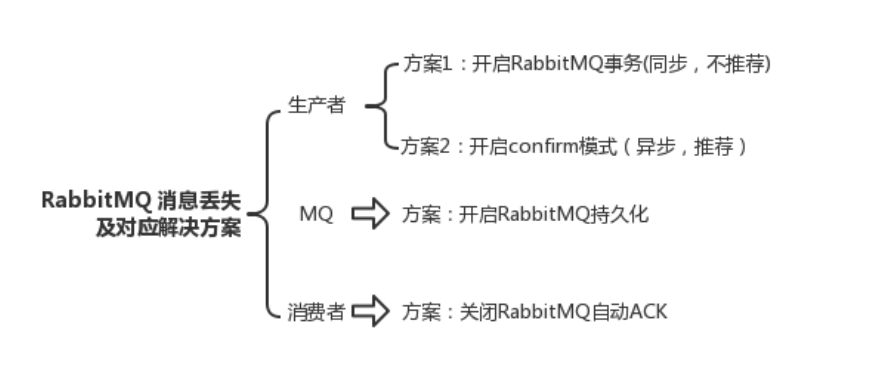
# 消息丢失(可靠性)
- 事前事中事后
# 顺序消费
一个topic下有多个队列,为了保证发送有序,RocketMQ提供了MessageQueueSelector队列选择机制,他有三种实现:
RocketMQ仅保证顺序发送,顺序消费由消费者业务保证!
一个队列有序出去,一个消费者消费不就好了? 消费者是多线程的,你消息是有序的给他的,你能保证他是有序的处理的?还是一个消费成功了再发下一个稳妥。
rabbimq
# 重复消费
原因
- 发给多个系统【库存、积分、活动】时,其他都处理成功但有一个【积分】处理失败(网络抖动,开发人员代码Bug等),触发mq重试。
解决方案
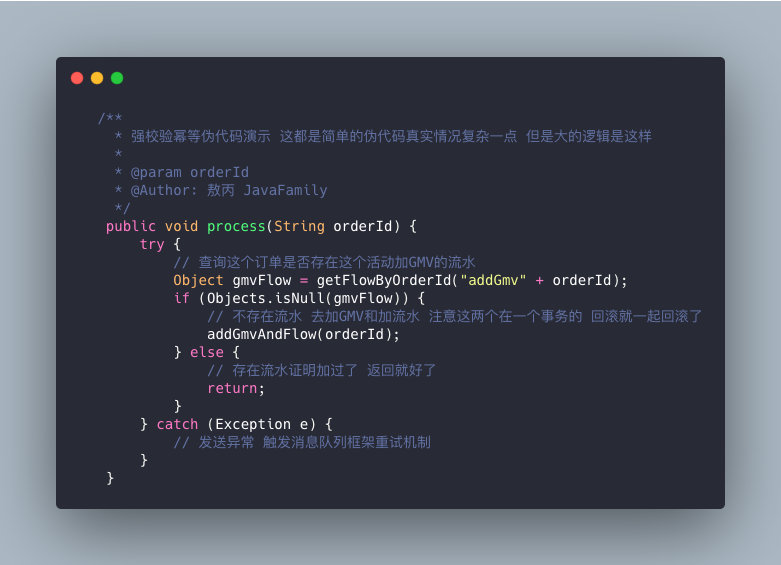
- 接口幂等(可以用redis做) + 唯一索引。(如下图引用傲丙强校验代码)
# 消息补偿机制
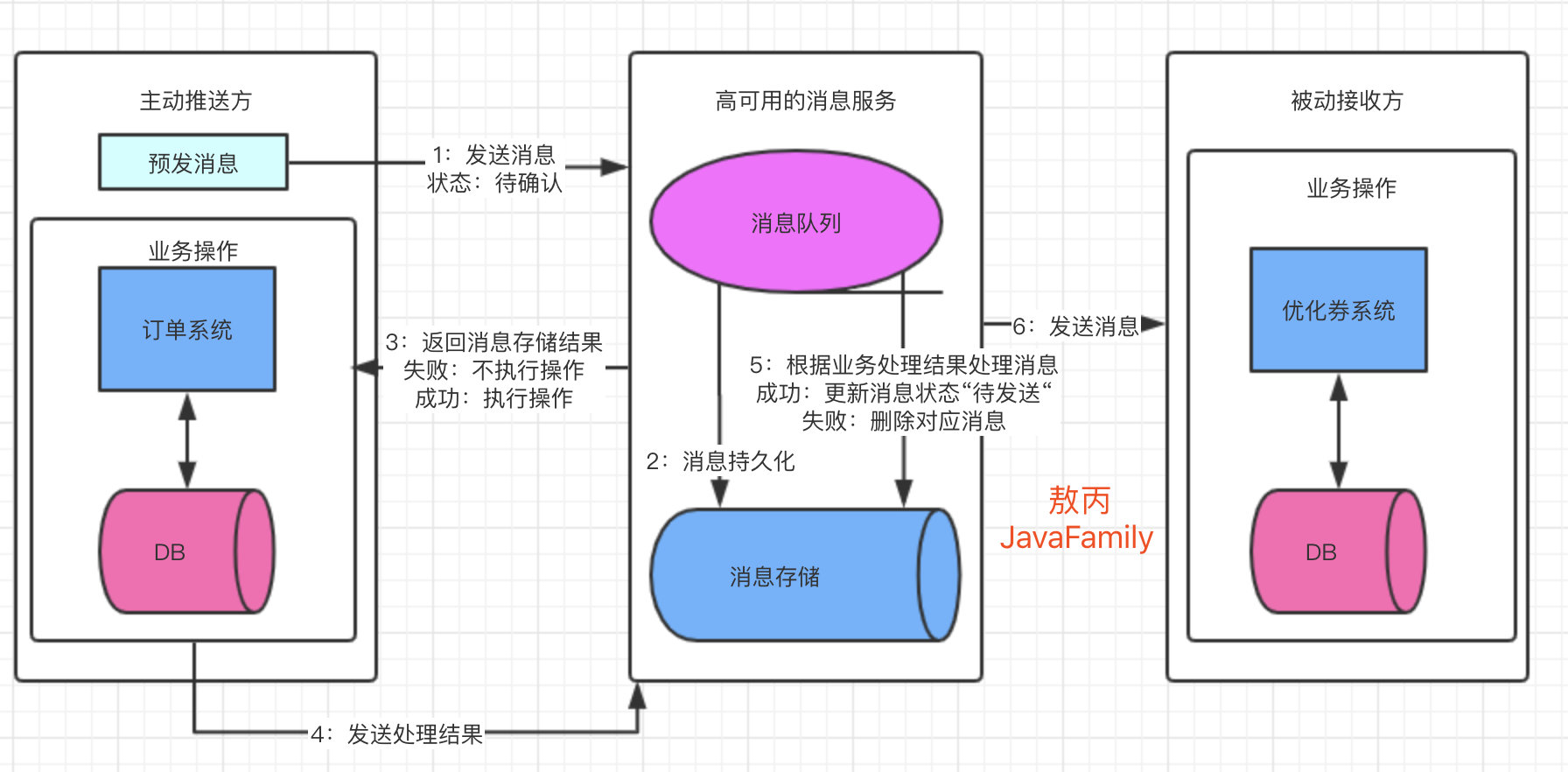
为啥要消息补偿:
生产者在准备发送MQ的时候,突然生产者宕机;
消息到达MQ后,正在准备持久化到硬盘的过程中MQ宕机了;
- 采用 定时轮询 + db 组合来重试(补偿)消息
- 数据库表里存一条消息的id,消费状态,重试次数,路由键,队列名,交换机名,消息体,生产时间,消费时间等字段。
- 消息补偿服务定时扫库:定时扫出状态为待消费、重试次数小于5次、生产时间大于5分钟的消息,这些消息才会重试。
- 生产者发送消息时先入库,状态为待消费;然后发送消息到MQ。
- MQ中间件正常接受消息,持久化,转发给消费者。
- 消费者收到消息后,判断消息的消费状态,消费后更新消息的消费状态。
# 大量数据消费
- 在rabbitMq中采用多个消费者,公平分发的模式去消费队列
# 如何保证高可用
定义
- 镜像集群模式:跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
开启
- 其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
缺点
- 1: 性能开销大: 因为需要进行整个集群内部所有实例的数据同步 2:无法线性扩容: 因为每一个服务器中都包含整个集群服务节点中的所有数据, 这样如果一旦单个服务器节点的容量无法容纳了怎么办?.
# 大量消息积压
- 一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
# 分布式事务
弊端
- 长时间锁定数据库资源,导致系统的响应不快,并发上不去
- 网络抖动出现脑裂情况,导致事物参与者,不能很好地执行协调者的指令,导致数据不一致。
- 单点故障:例如事物协调者,在某一时刻宕机,虽然可以通过选举机制产生新的Leader,但是这过程中,必然出现问题,而TCC,只有强悍的技术团队,才能支持开发,成本太高。
有多种类型
2pc(两段式提交)
- 2pc(两段式提交)可以说是分布式事务的最开始的样子了,像极了媒婆,就是通过消息中间件协调多个系统,在两个系统操作事务的时候都锁定资源但是不提交事务,等两者都准备好了,告诉消息中间件,然后再分别提交事务。
3pc(三段式提交)
TCC(Try、Confirm、Cancel)
最大努力通知
XA
本地消息表(ebay研发出的)
半消息/最终一致性(RocketMQ)
# 案例
订单和支付等
- 03
- 未来 10 年,哪些工作会被替代?哪些更稳?我们到底该焦虑什么04-15