Spring Gateway 宕机排查实录:SkyWalking Agent 引发的内存泄漏深度分析
# 背景介绍
在一次压测过程中,我们部署在生产环境中的 Spring Cloud Gateway 出现了频繁宕机,表现为:
- 请求响应超时
- 容器意外重启
- 无明显异常堆栈输出
- 日志记录不完整甚至缺失
初步怀疑为内存泄漏或 JVM 配置问题,随即启动一轮完整的排查流程。
服务已开启 Apache SkyWalking (opens new window) Agent,用于采集链路追踪、JVM 指标与应用日志。由于宕机频繁,决定深入定位 是否存在内存泄漏。
# 问题现象与初步诊断
现象:
Gateway 应用启动参数初始为
-Xmx512m后又增加到-Xmx1024m容器在高并发压测约 15 分钟内异常退出
docker inspect dky-gateway | grep -i "oom"显示OOMKilled=false,说明并非容器外部 OOM Killer 所致随后使用
top查看 Java 进程内存和 CPU 使用情况:java -Xmx1024m ... RES = 1.3g CPU = 500%+1
2
3均显示内存快速增长至近 1.3GB,超出了
-Xmx1024m限制,极有可能是 JVM 内存泄漏。
初步排查方向:
GC 日志未显示 FullGC
未检测到容器外部 OOM 杀死痕迹
怀疑为应用内部内存泄漏,故手动生成 Heap Dump (
.hprof) 文件jcmd <PID> GC.heap_dump /home/logs/gateway.hprof1
# Heap Dump 分析过程
使用 VisualVM 载入 .hprof 文件后,发现以下核心问题:
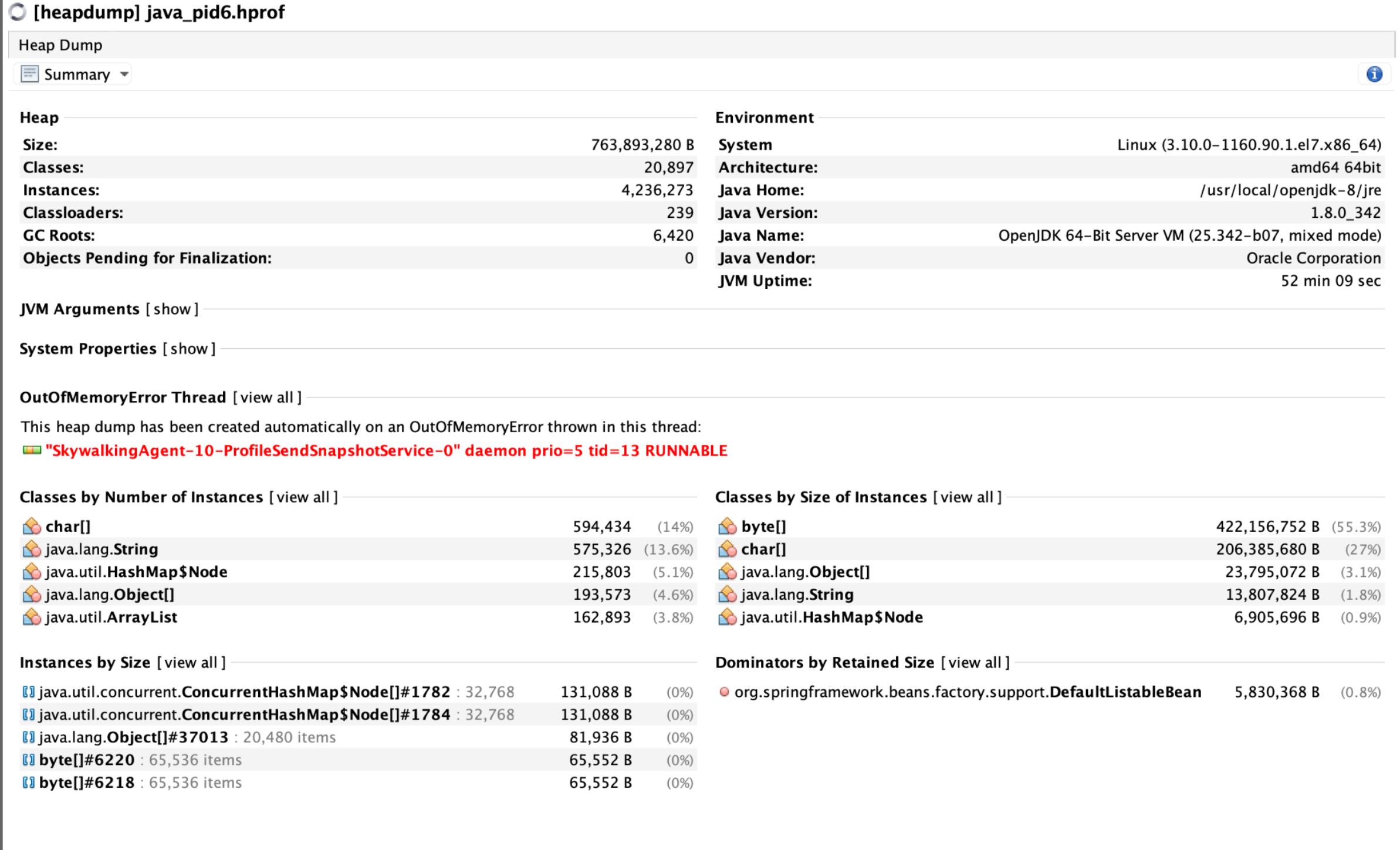
# 1. OOM 线程源
"SkywalkingAgent-10-ProfileSendSnapshotService-0" daemon tid=13 RUNNABLE
这是 SkyWalking 的 profile 功能线程,负责收集 trace 样本并发送快照 → 高度可疑是内存泄漏/积压点。
# 2. 大量 byte[] 堆积
- 占用内存:422MB(55.3%)
- 实例数:9.3 万
- 全部 retained:说明未被 GC 回收
# 3. GC Root 引用链指向 SkyWalking
我们点击某个 byte[] 实例查看引用链:
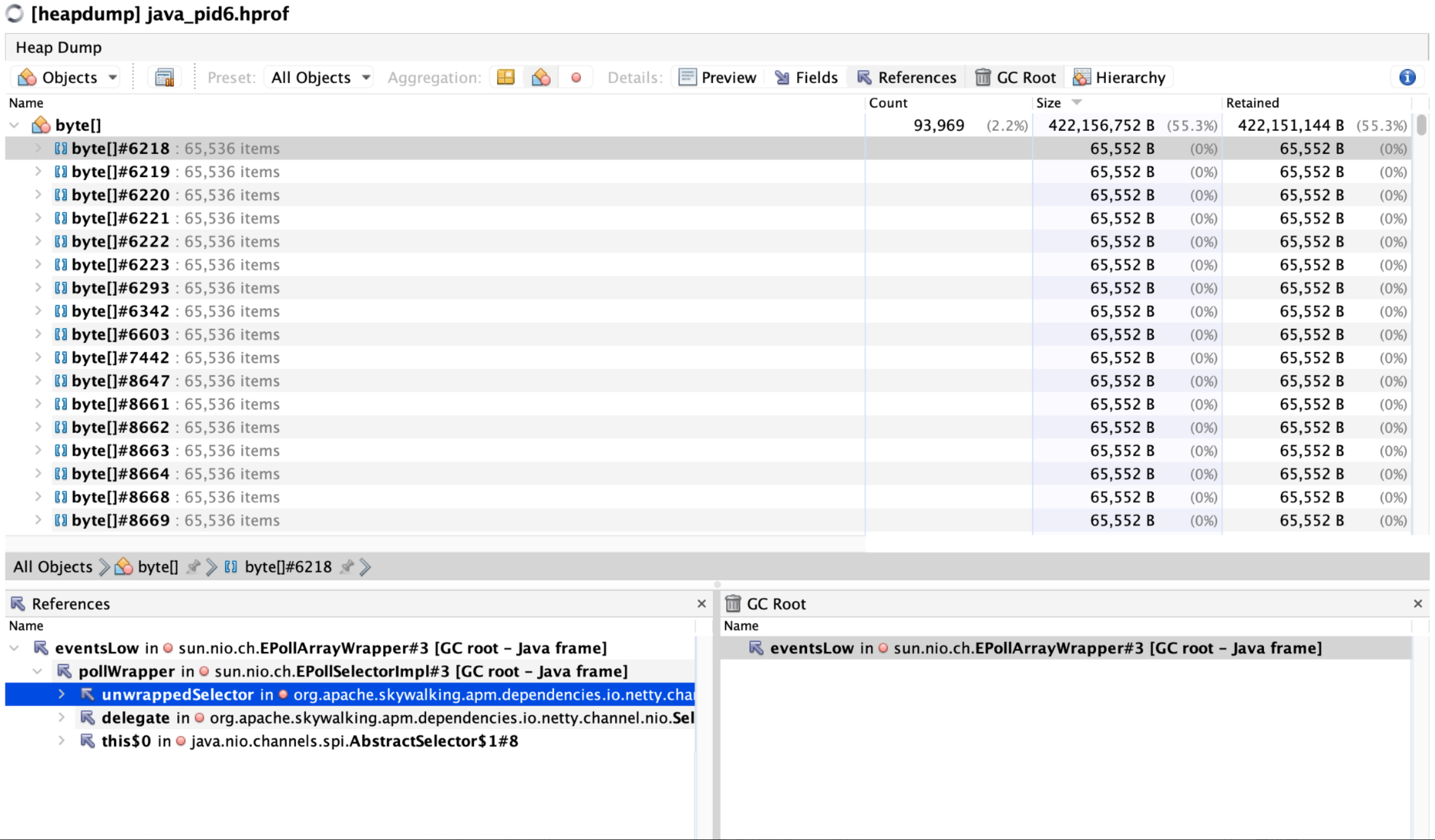
sun.nio.ch.EPollArrayWrapper#eventsLow [GC root - Java frame]
└── sun.nio.ch.EPollSelectorImpl#pollWrapper
└── org.apache.skywalking.apm.dependencies.io.netty.channel.nio.NioEventLoop#unwrappedSelector
└── byte[]
2
3
4
即:SkyWalking Agent 内部使用的 Netty Selector 事件缓冲未释放,导致内存持续增长,最终触发 OOM。
# SkyWalking Agent 配置审查
在分析其 agent.config 后确认:
- 开启了
profile.active=true→ Profile 快照任务占用大量内存 - 默认开启 trace 采样
agent.sample_n_per_3_secs=-1 - 未设置
keep_tracing=false,OAP 不可用时依然缓存数据 - 未关闭
meter.active=false,采集 JVM 指标增加内存压力
这些配置会在 OAP 不可用或发送失败时,导致大量 trace 数据堆积在本地缓存(HeapByteBuffer、byte[])。
# 最终根因
SkyWalking Agent 在开启 profile 功能 + 默认 trace 采样条件下,因连接不上 OAP 或处理不及时,造成 Netty Selector 中的数据缓冲无法及时清空,导致:
- 堆内
byte[]长期占用无法回收 - 堆内缓冲体积随压测剧增
- 最终触发 OOM
# 解决方案与优化建议
将如下配置写入 agent.config,并重启服务:
profile.active=false # 禁用 profile 模块(强烈建议)
agent.sample_n_per_3_secs=0 # 关闭 trace 采样
agent.keep_tracing=false # 断开后不缓存 trace
agent.span_limit_per_segment=50 # 限制 trace 单体大小
meter.active=false # 关闭 JVM 指标采集(视情况)
2
3
4
5
或使用环境变量注入:
environment:
- SW_AGENT_SAMPLE=0
- SW_AGENT_PROFILE_ACTIVE=false
- SW_AGENT_KEEP_TRACING=false
- SW_AGENT_SPAN_LIMIT=50
- SW_METER_ACTIVE=false
2
3
4
5
6
- SkyWalking Agent 应根据实际 OAP 状态决定缓存策略
- 监控工具建议提供缓冲区限流能力,防止泄漏
- 建议开启 GC 日志和
-XX:+HeapDumpOnOutOfMemoryError,便于快速定位问题
# 经验总结
| 教训 | 内容 |
|---|---|
| ☠️ 默认配置风险 | SkyWalking 默认开启 Profile/Trace 功能,在无 OAP 的场景下可能严重泄漏内存 |
| 🔍 可观测性 ≠ 稳定性 | 即使是监控工具,也可能因配置不当拖垮核心业务 |
| 💡 持续监控 agent 资源占用 | 使用 jstat、jmap、VisualVM 等工具进行定期回顾 |
| 🧹 保持配置精简 | 监控在生产环境中建议关闭无必要的特性(如 profile) |
- SkyWalking agent 在开启 profile 功能时,会通过 Netty 启动后台线程维护连接
- 若连接失败或网络不通,trace 数据会缓存在堆内 → 潜在高风险
- 内存泄漏不等于对象无用,而是“对象有用但永远不会释放”
# 附录
# JVM 启动参数建议:
-Xmx1024m
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/logs
-XX:+ExitOnOutOfMemoryError
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:/logs/gc.log
2
3
4
5
6
7
# 分析工具推荐
- Heap Dump 分析:VisualVM / Eclipse MAT
- 实时监控:jstat, jstack, jcmd
- 容器层日志查看:
docker logs,docker inspect
# 最后
这次事故为我们敲响了一个警钟:即使是成熟的探针工具,在未正确配置下也可能带来灾难性后果。 务必做到: “监控自身也需被监控,稳定性永远优先于可观察性。”

「真诚赞赏,手留余香」
# 打赏记录
| 打赏者 | 打助金额 (元) | 支付方式 | 时间 | 备注 |
|---|---|---|---|---|
| John | 12 | 微信 | 2020-06-09 | |
| 艾斯 | 32 | 支付宝 | 2020-07-11 | nice |
| HickSalmon | 15 | 微信 | 2020-09-21 | 有赏交流 |
- 03
- 未来 10 年,哪些工作会被替代?哪些更稳?我们到底该焦虑什么04-15