SpringBoot Prometheus 飞书告警对接
z 2026-01-09
监控告警
# 简介
环境: 在现有监控基础上,添加 Prometheus 告警集成 和 飞书告警
版本: 最新版。PrometheusAlert:https://github.com/feiyu563/PrometheusAlert。
Prometheus Alert 是开源的运维告警中心消息转发系统,支持主流的监控系统Prometheu,Zabbix,日志系统 Graylog 和数据可视化系统 Grafana 发出的预警消息,支持钉钉,微信,华为云短信,腾讯云短信,腾讯云电话,阿里云短信,阿里云电话等
监控:
- 监控,页面地址:http://124.70.95.70/grafana/d/sbapmwalker/springboot-apm-dashboard?orgId=1&from=now-30m&to=now
告警:
- 告警,PrometheusAlert 控制台:http://124.70.95.70/prometheus/alerts?search=
# Prometheus 告警
通过引入 alertmanager、prometheus-alert 和 prometheus 集成,实现告警规则配置和飞书告警
# 告警模块搭建
version: '2'
networks:
monitor:
driver: bridge
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
environment:
- TZ=Asia/Shanghai
volumes:
- ./prometheus/config:/etc/prometheus
- ./prometheus/data:/prometheus
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle'
ports:
- "9090:9090"
networks:
- monitor
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_AUTH_PROXY_ENABLED=true
# - GF_SERVER_SERVE_FROM_SUB_PATH=true
- GF_SERVER_ROOT_URL=http://localhost:3000/grafana
- TZ=Asia/Shanghai
ports:
- "3001:3000"
volumes:
- ./grafana:/var/lib/grafana
networks:
- monitor
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
environment:
- TZ=Asia/Shanghai
ports:
- "9093:9093"
volumes:
- ./prometheus/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
networks:
- monitor
prometheus-alert:
image: feiyu563/prometheus-alert:latest
container_name: prometheus-alert
restart: always
ports:
- "9094:8080"
volumes:
- ./prometheus/prometheus-alert/db:/app/db
environment:
- PA_LOGIN_USER=alertuser
- PA_LOGIN_PASSWORD=dk110
- PA_TITLE=Alert
- PA_OPEN_FEISHU=1
- PA_OPEN_DINGDING=0
- PA_OPEN_WEIXIN=1
networks:
- monitor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
# Prometheus 集成 alertmanager
更新配置文件 prometheus.yml,添加告警服务配置和告警规则文件配置
global:
scrape_interval: 30s # 每30s采集一次数据
evaluation_interval: 30s # 每30s做一次告警检测
# 告警服务
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.18:9093"]
# 告警规则文件
rule_files:
- "*_rules.yml"
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 告警规则
# Java服务告警规则
新建 java_rules.yml
# curl -X POST http://127.0.0.1:9090/-/reload
groups:
- name: java
rules:
- alert: JVM堆内存使用过高
expr: (sum by (instance)(jvm_memory_used_bytes{area="heap"}) / sum by (instance)(jvm_memory_max_bytes{area="heap"})) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
description: '服务 {{ $labels.job }} JVM 堆内存使用率超过 90% (当前使用 {{ $value }})'
- alert: JVM垃圾回收持续时间过长
expr: avg(rate(jvm_gc_duration_seconds_sum[5m])) by (job) > 2
for: 5m
labels:
severity: high
annotations:
description: '服务 {{ $labels.job }} JVM 垃圾回收持续时间超过 2 秒 (当前平均值 {{ $value }})'
- alert: SpringBoot健康检查失败
expr: http_server_requests_seconds_count{uri="/actuator/health", status="DOWN"} > 0
for: 5m
labels:
severity: critical
annotations:
description: '服务 {{ $labels.job }} Spring Boot 应用的健康检查失败,路径:{{ $labels.uri }}'
- alert: 请求响应时间过长
expr: http_server_requests_seconds_sum / http_server_requests_seconds_count > 3
for: 5m
labels:
severity: high
annotations:
description: '服务 {{ $labels.job }} 请求响应时间超过 3 秒,当前平均值:{{ $value }}秒'
- alert: HTTP 5xx 错误率过高
expr: rate(http_server_requests_seconds_count{status=~"5.."}[1m]) / rate(http_server_requests_seconds_count[1m]) > 0.05
for: 5m
labels:
severity: critical
annotations:
description: '服务 {{ $labels.job }} HTTP 5xx 错误率超过 5% (当前错误率:{{ $value }})'
- alert: CPU 使用过高
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 5
for: 5m
labels:
severity: critical
annotations:
description: '服务 {{ $labels.job }} CPU 使用率超过 5% (当前使用率:{{ $value }}%)'
- alert: 服务宕机
expr: up{job=~"dky-.*"} == 0
for: 1m
labels:
severity: emergency
level: critical
annotations:
description: '服务 {{ $labels.job }} 宕机'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 服务器告警规则
groups:
- name: node_alerts
rules:
- alert: 高CPU
expr: instance:node_cpu:avg_rate1m > 90
for: 5m
labels:
severity: warning
annotations:
summary: "实例 {{ $labels.instance }} CPU 使用率过高"
description: "实例 {{ $labels.instance }} CPU 使用率超过 90% (当前值为: {{ $value }})"
- alert: 磁盘还有7天满
expr: predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 7*24*3600) < 0
for: 5m
labels:
severity: critical
annotations:
summary: "Disk on {{ $labels.instance }} will fill in approximately 7 days. (当前值为: {{ $value }})"
- alert: 磁盘使用过载
expr: 1 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"}) > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "实例 {{ $labels.instance }} 磁盘使用率超过 90%"
description: "实例 {{ $labels.instance }} 磁盘使用率超过 90% (当前值为: {{ $value }})"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# Prometheus 告警规则
groups:
- name: prometheus_alerts
rules:
- alert: Prometheus 配置加载失败
expr: prometheus_config_last_reload_successful == 0
for: 1m
labels:
severity: warning
annotations:
description: Reloading Prometheus config has failed on {{ $labels.instance }}.
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 媒体服务器告警规则
groups:
- name: asterisk_alerts
rules:
- alert: 通话并发数超650
expr: instance:asterisk_calls_count:avg_rate1m > 650
for: 1m
labels:
severity: warning
annotations:
summary: "实例 {{ $labels.instance }} 通话并发数超过650"
description: "实例 {{ $labels.instance }} 通话并数发超650 (当前值为: {{ $value }})"
- alert: asterisk服务宕机
expr: up{job=~"dky-media"} == 0
for: 1m
labels:
severity: emergency
level: critical
annotations:
description: 'asterisk服务 {{ $labels.job }} 宕机'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
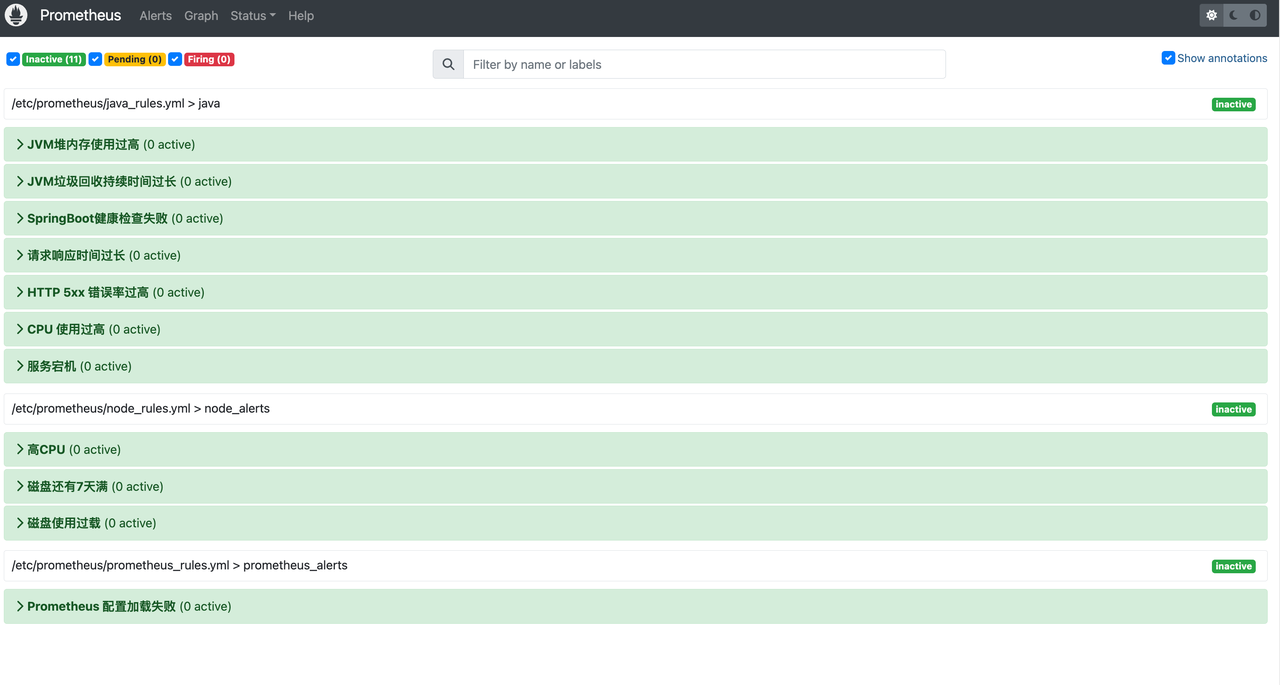
# 查看配置是否成功
打开Prometheus控制台页面,出现配置代表成功:http://124.70.95.70/prometheus/alerts?search=
# 飞书告警
通过 alertmanager 和 prometheus-alert 集成转发,来实现飞书告警
新建配置文件: alertmanager.yml
global:
resolve_timeout: 5m
route:
# 根节点的警报会发送给默认的接收组
# 该节点中的警报会按’instance’做 Group,每个分组中最多每5m发送一条警报,同样的警报最多10m发送一次
# 报警分组依据,根据 labael(标签)进行匹配,如果是多个,就要多个都匹配
group_by: ['instance']
# 组报警等待时间
group_wait: 10m
# 组报警间隔时间,为该组启动新的告警间隔时间
group_interval: 10s
# 重复报警间隔时间,告警发送成功后,下一次发送间隔时间
repeat_interval: 10m
receiver: 'web.hook.prometheusalert'
receivers:
- name: 'web.hook.prometheusalert'
webhook_configs:
- url: 'http://192.168.1.18:9094/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/f00a0244-f447-4655-85a6-d6d04d3ecccb'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
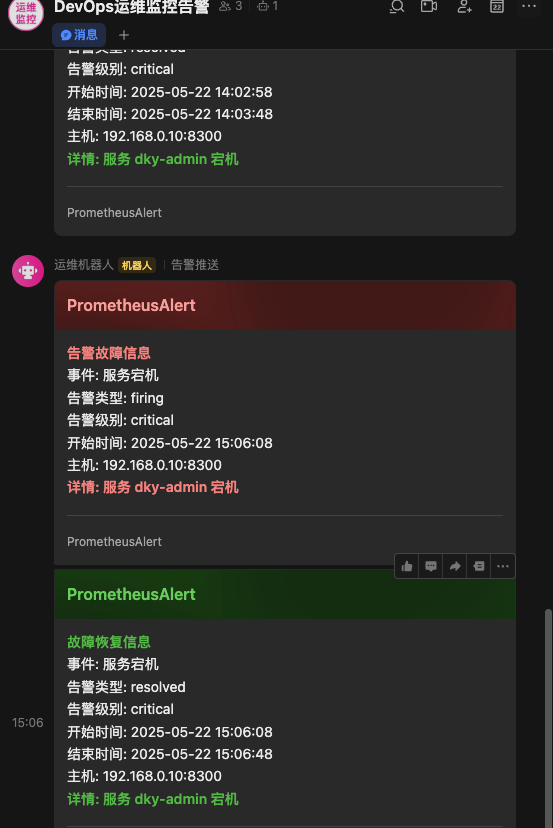
查看飞书通知:
# 添加 SpringBoot 所有 Java 服务监控
# 配置脚本,更新 prometheus.yml
global:
scrape_interval: 10s # 每30s采集一次数据
evaluation_interval: 10s # 每30s做一次告警检测
# 告警服务
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.18:9093"]
# 告警规则文件
rule_files:
- "*_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: [ '192.168.1.18:9090' ]
labels:
instance: prometheus
- job_name: 'cadvisor'
static_configs:
- targets: [ '192.168.1.18:8899' ]
- job_name: 'dev-中间件'
static_configs:
- targets: [ '192.168.1.18:9101' ]
- job_name: 'admin'
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: '/admin/actuator/prometheus'
static_configs:
- targets: [ '192.168.0.10:8300' ]
labels:
env: dev
project: DkCloud
- job_name: 'ws-sdk'
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: [ '192.168.0.10:8111', '192.168.0.10:8112' ]
labels:
env: dev
project: DkCloud
- job_name: 'open-api'
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: [ '192.168.0.10:8091' ]
labels:
env: dev
project: DkCloud
- job_name: 'gateway'
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: [ '192.168.0.10:8000' ]
labels:
env: dev
project: DkCloud
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
配置更新后,执行热加载命令即可生效
curl -X POST http://127.0.0.1:9090/-/reload
1
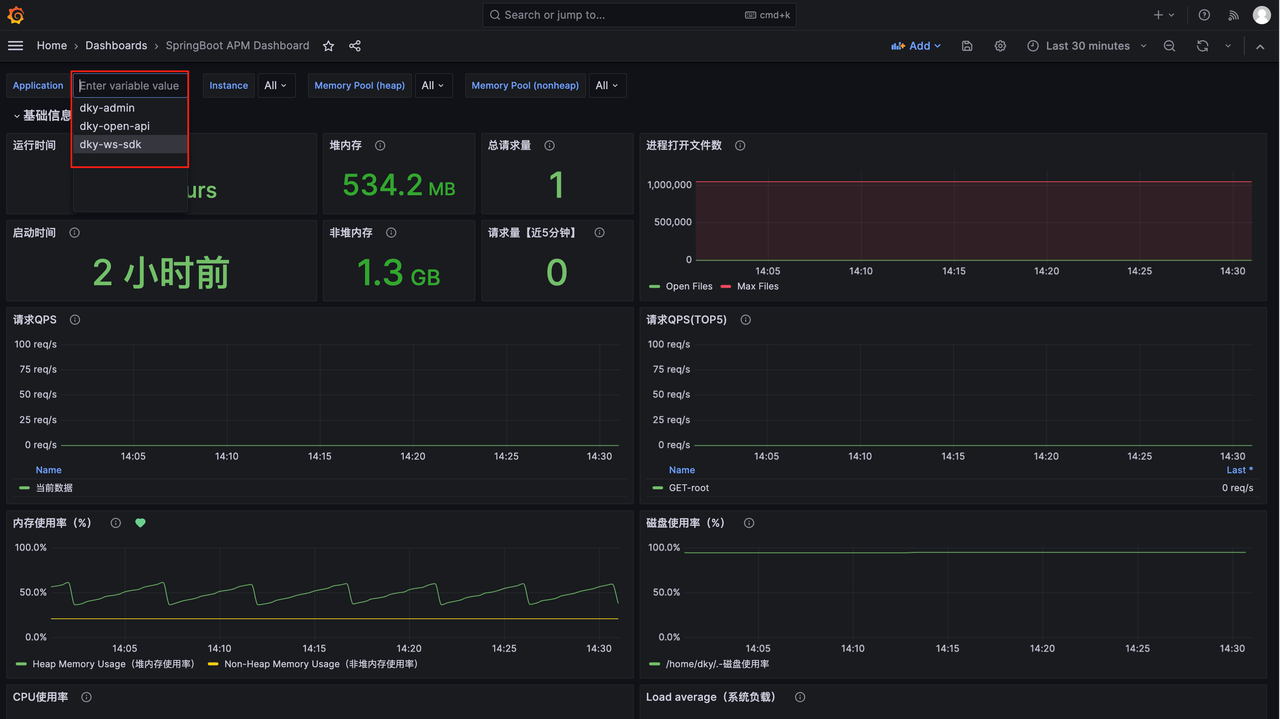
# 查看服务监控
配置变更完成后,等2分钟查看监控。配置变更后,多出了监控的 Java 服务:
# 遇到问题
虽然 PrometheusAlert 开源、普遍、用户数多,但是又调研了一下,发现滴滴开源的夜莺也更好更符合国情。
后期考虑改为部署夜莺:https://github.com/ccfos/nightingale,对接服务。
# 后续计划
部署夜莺监控告警。
赞赏一下

「真诚赞赏,手留余香」
# 打赏记录
| 打赏者 | 打助金额 (元) | 支付方式 | 时间 | 备注 |
|---|---|---|---|---|
| John | 12 | 微信 | 2020-06-09 | |
| 艾斯 | 32 | 支付宝 | 2020-07-11 | nice |
| HickSalmon | 15 | 微信 | 2020-09-21 | 有赏交流 |
- 03
- 未来 10 年,哪些工作会被替代?哪些更稳?我们到底该焦虑什么04-15