Kubernetes-2 组成
- 实例(Pod)
- 容器(Container)
- 工作负载
- 镜像(Image)
- 命名空间(Namespace)
- 服务(Service)
- 七层负载均衡(Ingress)
- 网络策略(NetworkPolicy)
- 配置项(Configmap)
- 密钥(Secret)
- 标签(Label)
- 标签选择器(LabelSelector)
- 注解(Annotation)
- 存储卷(PersistentVolume)
- 存储声明(PersistentVolumeClaim)
- 弹性伸缩(HPA)
- 亲和性与反亲和性
- 节点亲和性(NodeAffinity)
- 工作负载亲和性(PodAffinity)
- 工作负载反亲和性(PodAntiAffinity)
- 资源配额(Resource Quota)
- 资源限制(Limit Range)
- 环境变量
- 模板(Chart)
# 实例(Pod)
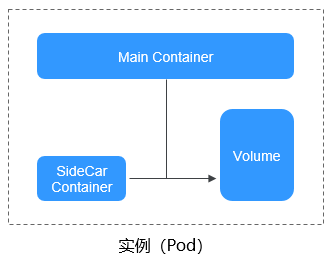
在Kubernetes中,Pod是部署应用或服务的最小基本单位。一个Pod可以封装一个或多个应用容器,多个容器通常共享存储和网络资源。每个Pod都有一个独立的网络IP地址,这使得 Pod内的容器可以相互通信,并且可以被集群内的其他Pod访问。同时,Kubernetes提供多种策略选项来管理容器的运行方式,包括重启策略、资源请求和限制、生命周期钩子等。
图 实例(Pod)
# 容器(Container)
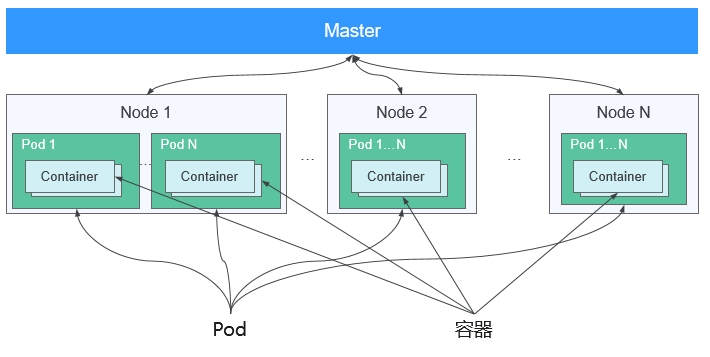
一个通过Docker镜像创建的运行实例被称为容器。在一个节点(宿主机)上可以运行多个容器。容器的实质是进程,但与直接在宿主机上执行的进程不同,容器进程运行于属于自己的独立的命名空间中。这些命名空间提供了一种隔离机制,使得每个容器都有自己的文件系统、网络接口、进程 ID 等,从而实现了操作系统级别的隔离。
图 实例Pod、容器Container、节点Node的关系
# 工作负载
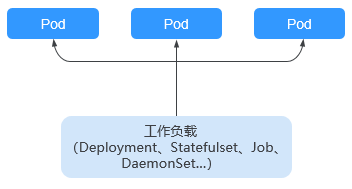
工作负载是在Kubernetes上运行的应用程序。无论您的工作负载是单个组件还是协同工作的多个组件,您都可以在Kubernetes上的一组Pod中运行它。在Kubernetes中,工作负载是对一组Pod的抽象模型,用于描述业务的运行载体,包括Deployment、StatefulSet、DaemonSet、Job、CronJob等多种类型。
无状态工作负载:即Kubernetes中的“Deployment”,无状态工作负载支持弹性伸缩与滚动升级,适用于实例完全独立、功能相同的场景,如Web服务器(NGINX)、博客平台(WordPress)等。
有状态工作负载:即Kubernetes中的“StatefulSet”,有状态工作负载支持实例有序部署和删除,每个Pod都有一个持久的标识符,并且可以相互通信,适用于需要持久化存储和实例间相互通信的应用,如分布式键值存储系统(ETCD)、高可用的数据库(MySQL-HA)等。
创建守护进程集:即Kubernetes中的“DaemonSet”,守护进程集确保全部(或者某些)节点都运行一个Pod实例,支持会自动将Pod部署到新加入集群的节点上,它适用于需要在每个节点上运行的服务,如日志收集(fluentd)、监控代理(Prometheus Node Exporter)等。
普通任务:即Kubernetes中的“Job”,普通任务是一次性运行的任务,确保指定数量的Pod成功完成执行。适用于需要在集群中执行一次性任务的场景,如数据备份、批量处理等。
定时任务:即Kubernetes中的“CronJob”,定时任务是按照指定时间周期运行的任务。适用于需要定期执行的任务,如定时数据同步、定时生成报告等。
图 工作负载与Pod的关系
# 镜像(Image)
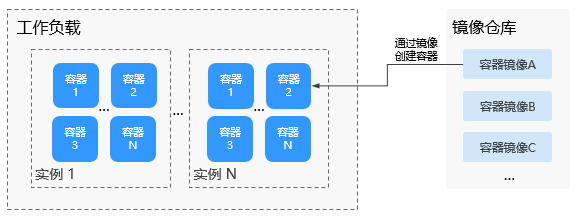
镜像(Image)是一个模板,是容器应用打包的标准格式,用于创建容器。或者说,镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。在部署容器化应用时可以指定镜像,镜像可以来自于 Docker Hub、容器镜像服务或者用户的私有镜像仓库。例如,开发者可以创建一个包含特定应用程序及其所有依赖的镜像,确保在任何环境中都能以相同的方式运行。
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
图 镜像、容器、工作负载的关系
# 命名空间(Namespace)
命名空间是对一组资源和对象的抽象整合,允许您将相关的资源和对象(如Pods、Services、Deployments等)组织在一起,形成一个逻辑上的分组。不同命名空间中的数据彼此隔离,但它们仍可以共享同一个集群的基础资源(如CPU、内存、存储等)。您可以在不同的命名空间中部署不同的环境,例如开发环境、测试环境和生产环境,这样可以确保环境之间的隔离,同时便于管理和维护。
在Kubernetes中,大部分资源对象都是命名空间级别的,如Pods、Services、Replication Controllers和Deployments等,这意味着它们属于某一个命名空间(默认是default)。但仍有一部分资源是集群级别的,例如Node、PersistentVolumes等,它们不属于任何命名空间,为所有命名空间中的资源提供服务。
# 服务(Service)
在Kubernetes中,Service用于定义Pods的访问策略。Service类型的取值以及行为如下:
ClusterIP:这是默认的Service类型,它会在集群内部为Service分配一个唯一的IP地址。这个IP地址只在集群内部可用,外部无法直接访问。ClusterIP类型的Service通常用于集群内部的通信。
NodePort:NodePort类型的Service会在集群的所有节点上打开一个静态端口(NodePort),通过这个端口可以访问Service。这个类型的Service允许外部流量通过节点绑定的弹性IP和指定的端口访问Service,从而实现对外提供服务。
LoadBalancer:利用云服务提供商的负载均衡器,将Service暴露给外部网络。外部的负载均衡器可以将流量转发到集群中NodePort服务和ClusterIP服务。
DNAT:使用DNAT网关为集群节点提供网络地址转换服务,使多个节点可以共享使用弹性IP。与直接为节点绑定弹性IP的方式相比,DNAT方式增强了可靠性,弹性IP无需与单个节点绑定,任何节点状态的异常不影响其访问。
# 七层负载均衡(Ingress)
Ingress是为进入集群的请求提供路由规则的集合,可以给service提供集群外部访问的URL、负载均衡、SSL终止、HTTP路由等。
# 网络策略(NetworkPolicy)
NetworkPolicy提供了基于策略的网络控制,用于隔离应用并减少攻击面。它使用标签选择器模拟传统的分段网络,并通过策略控制它们之间的流量以及来自外部的流量。
# 配置项(Configmap)
ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。ConfigMap跟Secret很类似,但它可以更方便地处理不包含敏感信息的字符串。
# 密钥(Secret)
Secret解决了密码、Token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。Secret可以通过Volume或者环境变量的方式使用。
# 标签(Label)
在Kubernetes中,标签(Label)是附加到资源对象(如Pod、Service、Deployment等)上的键值对。标签的主要作用是为这些对象提供额外的、语义化的元数据,以便于用户和系统能够更容易地识别、组织和管理资源。
# 标签选择器(LabelSelector)
在Kubernetes中,标签选择器是一种强大的机制,极大地简化了资源管理和操作的复杂性。它允许用户根据资源对象上的标签来选择和分组这些对象,可以对选中的资源组执行批量操作,如流量分配、扩缩容、更新配置、监控状态等。
# 注解(Annotation)
Annotation与Label类似,也使用key/value键值对的形式进行定义。但它们在用途和约束上有所不同。
Label更多地用于资源的选择和管理,具有严格的命名规则,它定义的是Kubernetes对象的元数据(Metadata),并且用于Label Selector为用户提供选择资源的能力。
Annotation则是用户任意定义的“附加”信息,Kubernetes系统不会直接使用这些注解来控制资源的行为,但它存储的额外信息可以被外部工具获取,用于扩展Kubernetes的功能。
# 存储卷(PersistentVolume)
PersistentVolume(PV)是集群的一块存储资源,可以是本地磁盘或网络存储。它具有独立于Pod的生命周期,这意味着即使使用PV的Pod被删除,PV中的数据也不会丢失。
# 存储声明(PersistentVolumeClaim)
PersistentVolumeClaim (PVC) 用户对存储资源PV的请求,它指定了存储的大小、访问模式等要求,Kubernetes会自动匹配合适的PV来满足这些要求。
PV和PVC之间的关系类似于Pod和Node的关系:Pod消耗Node资源,而PVC消耗PV资源。
# 弹性伸缩(HPA)
Horizontal Pod Autoscaling,简称HPA,是Kubernetes中实现POD水平自动伸缩的功能。HPA允许Kubernetes集群根据CPU使用率、内存使用率或其他选择的指标自动增加或减少 Pod 的数量。您可以设置目标指标的阈值,HPA会根据这些阈值自动调整Pod的数量,以保持应用的性能。
# 亲和性与反亲和性
在应用没有容器化之前,原先一个虚机上会装多个组件,进程间会有通信。但在做容器化拆分的时候,往往直接按进程拆分容器,比如业务进程一个容器,监控日志处理或者本地数据放在另一个容器,并且有独立的生命周期。这时如果分布在网络中两个较远的点,请求经过多次转发,性能会很差。
亲和性:可以实现就近部署,增强网络能力实现通信上的就近路由,减少网络的损耗。如:应用A与应用B两个应用频繁交互,所以有必要利用亲和性让两个应用尽可能地靠近,甚至在一个节点上,以减少因网络通信而带来的性能损耗。
反亲和性:主要是出于高可靠性考虑,尽量分散实例,某个节点故障的时候,对应用的影响只是 N 分之一或者只是一个实例。如:当应用采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个节点上,以提高HA。
# 节点亲和性(NodeAffinity)
通过选择标签的方式,可以限制Pod被调度到特定的节点上。
# 工作负载亲和性(PodAffinity)
指定工作负载部署在相同节点。用户可根据业务需求进行工作负载的就近部署,容器间通信就近路由,减少网络消耗。
# 工作负载反亲和性(PodAntiAffinity)
指定工作负载部署在不同节点。同个工作负载的多个实例反亲和部署,减少宕机影响;互相干扰的应用反亲和部署,避免干扰。
# 资源配额(Resource Quota)
资源配额(Resource Quotas)允许管理员为命名空间设置资源使用总和的限制,例如CPU、内存、磁盘空间和网络带宽等。
# 资源限制(Limit Range)
默认情况下,K8s中所有容器都没有任何CPU和内存限制。LimitRange用来给命名空间中的对象(如Pod等)增加资源限制。
LimitRange对象提供的限制能够实现以下能力:
在一个命名空间中对每个Pod或容器的最小/最大资源使用量进行限制。
在一个命名空间中对每个PersistentVolumeClaim能申请的最小/最大存储空间进行限制。
在一个命名空间中对一种资源的申请值和限制值的比值进行控制。
设置一个命名空间中对计算资源的默认申请/限制值,并且自动在运行时注入到多个容器中。
# 环境变量
环境变量是指容器运行环境中设定的一个变量,您可以在创建容器模板时设定不超过30个的环境变量。环境变量可以在工作负载部署后修改,为工作负载提供了极大的灵活性。
在CCE中设置环境变量与Dockerfile中的“ENV”效果相同。
# 模板(Chart)
Kubernetes集群可以通过Helm (opens new window)实现软件包管理,这里的Kubernetes软件包被称为模板(Chart)。Helm对于Kubernetes的关系类似于在Ubuntu系统中使用的apt命令,或是在CentOS系统中使用的yum命令,它能够快速查找、下载和安装模板(Chart)。
模板(Chart)是一种Helm的打包格式,它只是描述了一组相关的集群资源定义,而不是真正的容器镜像包。模板中仅仅包含了用于部署Kubernetes应用的一系列YAML文件,您可以在Helm模板中自定义应用程序的一些参数设置。在模板的实际安装过程中,Helm会根据模板中的YAML文件定义在集群中部署资源,相关的容器镜像并不会包含在模板包中,而是依旧从YAML中定义好的镜像仓库中进行拉取。
对于应用开发者而言,需要将容器镜像包发布到镜像仓库,并通过Helm的模板将安装应用时的依赖关系统一打包,预置一些关键参数,来降低应用的部署难度。
对于应用使用者而言,可以使用Helm查找模板(Chart)包并支持调整自定义参数。Helm会根据模板包中的YAML文件直接在集群中安装应用程序及其依赖,应用使用者不用编写复杂的应用部署文件,即可以实现简单的应用查找、安装、升级、回滚、卸载。

「真诚赞赏,手留余香」
# 打赏记录
| 打赏者 | 打助金额 (元) | 支付方式 | 时间 | 备注 |
|---|---|---|---|---|
| John | 12 | 微信 | 2020-06-09 | |
| 艾斯 | 32 | 支付宝 | 2020-07-11 | nice |
| HickSalmon | 15 | 微信 | 2020-09-21 | 有赏交流 |
- 03
- 未来 10 年,哪些工作会被替代?哪些更稳?我们到底该焦虑什么04-15